Las empresas detrás de los modelos de inteligencia artificial (IA) como ChatGPT, Gemini y Meta AI han estado acumulando grandes volúmenes de datos de diversas fuentes para mejorar sus respuestas. Esta práctica ha llevado a una serie de litigios en los tribunales, donde están en juego miles de millones de dólares y el futuro del modelo de negocio de la IA. La estrategia de “mejor pedir perdón que permiso” se ha vuelto común en el sector, y ahora enfrenta un intenso escrutinio legal.
En la actualidad, más de 100 demandas activas están desafiando esta práctica, muchas de ellas centradas en si el entrenamiento de modelos de IA con contenido protegido puede considerarse un uso justo. Este debate se desarrolla principalmente en tribunales de Estados Unidos, donde la defensa de empresas como OpenAI se basa en el “uso justo” y las excepciones de minería de datos. Sin embargo, cada caso se juzga de manera individual, y el resultado podría obligar a las empresas a pagar licencias retroactivamente y a cambiar la forma en que recopilan datos.
A diferencia de Estados Unidos, Europa aplica regulaciones más estrictas sobre la gestión de datos, exigiendo que sean eliminados tras su uso y permitiendo que los creadores mantengan sus derechos. La AI Act europea también requiere que se especifique qué datos fueron utilizados en el entrenamiento de modelos, algo que muchas empresas han evadido hasta el momento.
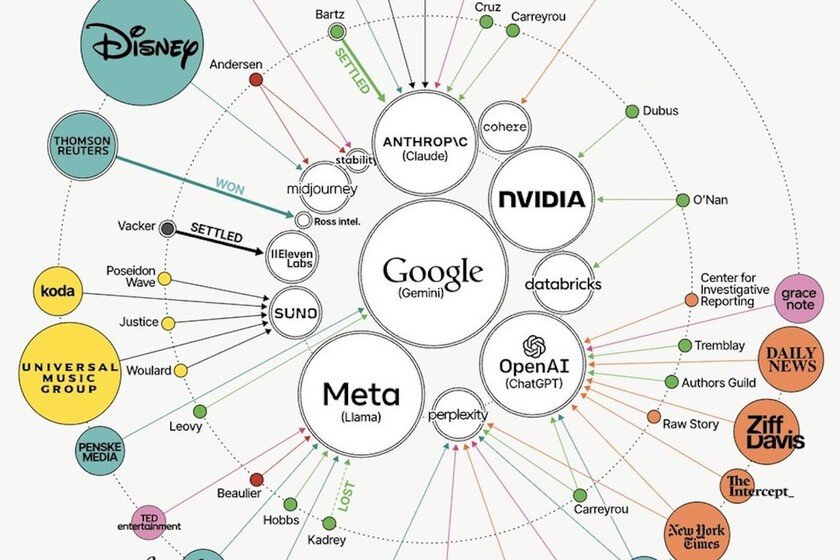
Un gráfico elaborado por David McCandless muestra el entramado de estas demandas, con las empresas tecnológicas demandadas en el centro y los demandantes alrededor. Entre los demandantes se encuentran escritores, medios de comunicación y artistas, que alegan que sus obras fueron utilizadas sin autorización para entrenar sistemas que actualmente compiten con ellos. Este gráfico proporciona una visualización clara de quién está demandando a quién en el sector de la IA.
Los conflictos abarcan desde denuncias de que contenidos protegidos fueron utilizados sin permiso para entrenar modelos de aprendizaje automático, hasta casos en curso, como el de New York Times contra OpenAI, donde se aborda si ChatGPT reproduce artículos casi de manera literal. Otros ejemplos incluyen a Disney enfrentándose a Midjourney sobre generación de imágenes y a discográficas demandando a Anthropic por reproducción de letras.
La Oficina de Derechos de Autor de EE.UU. ha señalado que no hay una solución única y que cada caso debe ser analizado de forma independiente. A medida que este debate continúa, se plantean preguntas sobre si se establecerán normas más claras sobre la recopilación y uso de datos en el futuro de la inteligencia artificial.